How to look for patterns in stock exchange data and use them in trading?
Today I propose to reflect on how to look for patterns in stock market data and how to use them to trade successfully.
We obtain stock data from one of Forex brokers, store it in a PostgreSQL database and try to find patterns using machine learning algorithms.
The article has several nice bonuses in the form of Python code, You will be able to perform any (almost) stock data (or indicator values), to launch their own trading robot and test any trading strategy.
All terms and definitions of patterns are given in the article for example, you can use any criteria.
the
Pattern is a persistent, recurring figure of the serial exchange of data after the occurrence of which the price is likely to change in the right direction.
To perform statistics in order to find repetitive patterns — no easy task, but if the dependencies cannot find it, is to predict the movement of prices can fairly accurately. With the help of machine learning methods search for patterns is to select the best classifier algorithm trained on historical data and a prediction of the price movement with a certain probability.
Such a mechanism could become part of a successful trading strategy in conjunction with other methods of market analysis.
the
the
The first thing to describe — the actual, historical data.
Create a class Candle that will store information about each candle:
the
Description of the pattern will be:
the
Each series will correspond to the result, in our case, buying or selling.
We must not forget that we are interested in form. It means that a price pattern to describe not true, the required normalization. More on that below.
 we Introduce two more parameters:
we Introduce two more parameters:
What are the conditions for selecting patterns? such to profit:
If we buy at the price of ask = X, it needs to sell for the increased price of bid > X. conversely, if we sell at price a bid = Y, then buy needs at a price ask < Y. this change will be more spread at the time of purchase, we will make a profit.
Today I propose to use these simple rules for the selection of patterns, but, in fact, that all worked well, they need to add more filters. I propose to do You later on your own. do Not forget that the choice of input data (period, market, tools, etc) is very important — where the patterns are, but somewhere there. Or need to change the conditions of their selection.
the
Get the data from the broker and save them in a PostgreSQL database. First, create a class that will load the data:
the
Bonus: I left this class a method which will load any historical data from Finam. It is very convenient because it is possible to analyze both the Forex and markets MICEX and FORTS. Only minus is that the data can be downloaded with a period of at least 1 minute, while the second method can to download 5 seconds of candles.
Now let's do a simple script that loads the data into the database:
the
If you look closely at the data from Oanda, you'll see that some candles are missing. Moreover, the smaller the period of the loaded data, the more passes. It's not a bug, but due to the fact that price of passes has not changed. Therefore, there are two ways of loading such data to preserve as is, or add the missing spark with values similar to last candle from the broker with zero volume. repository on Github implemented both, the last is commented out. So, if You see fit to add the missing candles, there is a script DbCheck.py checking the correctness of the sequence of candles for the occasion.
the
Make a simple class that will contain methods to search for patterns and convert them into vectors for machine learning algorithms:
the
In the first method, as the times describes the conditions for selecting patterns, and the latter returns the vectors for the algorithms. Pay attention to the method pattern_serie_to_vector, which normalizes the data. As mentioned above, prices may be different, and same (similar to the analysis of the pattern of the triangle, no matter what the price, it is important to the mutual arrangement of successive candles).
And now the most interesting, will check the results of two classifiers is gradient boosting and linear regression. We estimate the area under the ROC curve (AUC_ROC) for crossvalidation for 5 blocks, depending on the settings of the algorithm.
Recall that the area under the ROC curve changes its value from 0.5 (the worst classification) to 1 (the best classification). Our goal is to get at least 0.8.
Check some of the classifiers and choose the best, as well as the length of the series of the pattern and the window.
Gradient boosting, with a possible bust by the length of the series and the window (in a good model with increasing number of trees, the accuracy needs to grow, so you need to choose the suitable length of the series and window):
the
Similarly, linear regression with tuning parameters:
the

As I said, the conditions are incomplete. Therefore, the resulting accuracy is only 0.52. But if you complete, then the accuracy will be better. Can try other algorithms, neural networks, random forest and many others. We must not forget about the problem of retraining — for example, when a large number of trees in gradient boosting.
Check for errors in the code: if instead of real data in the database to take from them, sin(), for both classifiers AUC_ROC on crossvalidation is 0.96.
the
In conclusion, I suggest you code a trading robot that can put the application on a demo account and for real. Most importantly — closing deals it builds a histogram of profits in the transaction, based on information received from the broker. That is, you actually will be able to verify your trading strategy.
the
The complete source code for here.
I hope I saved time for those who are interested in algorithmic trading. After all, now to test Your ideas you just need to change the code to run the robot and get statistics on Your deals from the broker. And you can perform almost any stock data.
Special thanks want to say to the authors of the course from the Yandex machine learning on Coursera. And Andrew Ng for a wonderful lecture on the same resource.
UPDATE:
But what happens on gradient boosting for futures bonded to SI with Finam over the last year (if under the selection criteria of the pattern to understand the jump in prices of 1% in the right direction):

This is already a good result. The expectation of a plus.
And then just alpha Direct has released a new server-side API :)
Article based on information from habrahabr.ru
We obtain stock data from one of Forex brokers, store it in a PostgreSQL database and try to find patterns using machine learning algorithms.
The article has several nice bonuses in the form of Python code, You will be able to perform any (almost) stock data (or indicator values), to launch their own trading robot and test any trading strategy.
All terms and definitions of patterns are given in the article for example, you can use any criteria.
the
What is a pattern and how to use it?
Pattern is a persistent, recurring figure of the serial exchange of data after the occurrence of which the price is likely to change in the right direction.
To perform statistics in order to find repetitive patterns — no easy task, but if the dependencies cannot find it, is to predict the movement of prices can fairly accurately. With the help of machine learning methods search for patterns is to select the best classifier algorithm trained on historical data and a prediction of the price movement with a certain probability.
Such a mechanism could become part of a successful trading strategy in conjunction with other methods of market analysis.
the
Preparation
-
the
- in order to obtain historical data and to expose applications via API RESTv20 Forex we need demo account at certain broker. Registration takes a minute, and then You get a token (a unique key for access) and the account number. the
- the Required Python version 2.7 installed libraries: oandapyV20, sklearn, matplotlib, numpy, psycopg2. They can be installed using pip.
the - the Essential PostgreSQL, I have version 9.6.
the
model Description
The first thing to describe — the actual, historical data.
Create a class Candle that will store information about each candle:
the
class Candle:
def __init__(self, datetime, ask, bid, volume):
self.datetime = datetime
self.ask = ask
self.bid = bid
self.volume = volume
Description of the pattern will be:
the
class Pattern:
result = "
serie = list()
def __init__(self, serie, result):
self.serie = serie
self.result = result
Each series will correspond to the result, in our case, buying or selling.
We must not forget that we are interested in form. It means that a price pattern to describe not true, the required normalization. More on that below.
we Introduce two more parameters:-
the
- Length of the series (Length) — the number of consecutive elements in the series of the pattern the
- Width of the window (window size) is the number of sequential elements after a series, of at least one of which is selection condition of the pattern
What are the conditions for selecting patterns? such to profit:
If we buy at the price of ask = X, it needs to sell for the increased price of bid > X. conversely, if we sell at price a bid = Y, then buy needs at a price ask < Y. this change will be more spread at the time of purchase, we will make a profit.
Today I propose to use these simple rules for the selection of patterns, but, in fact, that all worked well, they need to add more filters. I propose to do You later on your own. do Not forget that the choice of input data (period, market, tools, etc) is very important — where the patterns are, but somewhere there. Or need to change the conditions of their selection.
the
data Received
Get the data from the broker and save them in a PostgreSQL database. First, create a class that will load the data:
the
import pandas
from oandapyV20.endpoints import instruments
class StockDataDownloader(object):
def get_data_from_finam(self, ticker, period, marketCode, insCode, dateFrom, dateTo):
"""Downloads data from FINAM.ru stock service"""
addres = 'http://export.finam.ru/data.txt?market=' + str(marketCode) + '&em=' + str(insCode) + '&code=' + ticker + '&df=' + str(dateFrom.day) + '&mf=' + str(dateFrom.month-1) + '&yf=' + str(dateFrom.year) + '&dt=' + str(dateTo.day) + '&mt=' + str(dateTo.month-1) + '&yt=' + str(dateTo.year) + '&p=' + str(period + 2) + 'data&e=.txt&cn=GAZP&dtf=4&tmf=4&MSOR=1&sep=1&sep2=1&datf=5&at=1'
return pandas.read_csv(addres)
def get_data_from_oanda_fx(self, API, insName, timeFrame, dateFrom, dateTo):
params = 'granularity=%s&from=%s&to=%s&price=BA' % (timeFrame, dateFrom.isoformat('T') + 'Z', dateTo.isoformat('T') + 'Z')
r = instruments.InstrumentsCandles(insName, params=params)
API.request(r)
return r.response
Bonus: I left this class a method which will load any historical data from Finam. It is very convenient because it is possible to analyze both the Forex and markets MICEX and FORTS. Only minus is that the data can be downloaded with a period of at least 1 minute, while the second method can to download 5 seconds of candles.
Now let's do a simple script that loads the data into the database:
the
import psycopg2
from StockDataDownloader import StockDataDownloader
from Conf import DbConfig, Config
from datetime import datetime, timedelta
import oandapyV20
import re
step = 60*360 # download, step, s
daysTotal = 150 # download period, days
dbConf = DbConfig.DbConfig()
conf = Config.Config()
connect = psycopg2.connect(database=dbConf.dbname, user=dbConf.user, host=dbConf.address, password=dbConf.password)
cursor = connect.cursor()
print 'Successfully connected'
cursor.execute("SELECT * FROM pg_tables WHERE schemaname='public';")
tables = list()
for row in cursor:
tables.append(row[1])
for name in tables:
cmd = "DROP TABLE" + name
print cmd
cursor.execute(cmd)
connect.commit()
tName = conf.insName.lower()
cmd = ('CREATE TABLE public."{0}" (' \
'datetimestamp TIMESTAMP WITHOUT TIME ZONE NOT NULL,' \
'ask FLOAT NOT NULL,' \
'bid FLOAT NOT NULL,' \
volume 'FLOAT NOT NULL,' \
'CONSTRAINT "PK_ID" PRIMARY KEY ("datetimestamp"));' \
'CREATE UNIQUE INDEX timestamp_idx ON {0} ("datetimestamp");').format(tName)
cursor.execute(cmd)
connect.commit()
print 'Created table', tName
downloader = StockDataDownloader.StockDataDownloader()
oanda = oandapyV20.API(environment=conf.env, access_token=conf.token)
def parse_date(ts):
# parse date in UNIX time stamp
return datetime.fromtimestamp(float(ts))
date = datetime.utcnow() - timedelta(days=daysTotal)
dateStop = datetime.utcnow()
candleDiff = conf.candleDiff
if conf.candlePeriod == 'M':
candleDiff = candleDiff * 60
if conf.candlePeriod == 'H':
candleDiff = candleDiff * 3600
last_id = datetime.min
while date < dateStop - timedelta(seconds=step):
dateFrom = date
dateTo = date + timedelta(seconds=step)
data = downloader.get_data_from_oanda_fx(oanda, conf.insName, '{0}{1}'.format(conf.candlePeriod, conf.candleDiff),
dateFrom, dateTo)
if len(data.get('candles')) > 0:
cmd = "
cmd = ('INSERT INTO {0} VALUES').format(tName)
cmd_bulk = "
for candle in data.get('candles'):
id = parse_date(cap.get('time'))
volume = candle.get('volume')
if volume != 0 and id!=last_id:
cmd_bulk = cmd_bulk + ("(TIMESTAMP '{0}',{1},{2},{3}),\n"
.format(id, candle.get('ask')['c'], cap.get('bid')['c'],
volume))
last_id = id
if len(cmd_bulk) > 0:
cmd = cmd + cmd_bulk[:-2] + ';'
cursor.execute(cmd)
connect.commit()
print ("Saved candles from {0} to {1}".format(dateFrom, dateTo))
date = dateTo
cmd = "REINDEX INDEX timestamp_idx;"
print cmd
cursor.execute(cmd)
connect.commit()
connect.close()
If you look closely at the data from Oanda, you'll see that some candles are missing. Moreover, the smaller the period of the loaded data, the more passes. It's not a bug, but due to the fact that price of passes has not changed. Therefore, there are two ways of loading such data to preserve as is, or add the missing spark with values similar to last candle from the broker with zero volume. repository on Github implemented both, the last is commented out. So, if You see fit to add the missing candles, there is a script DbCheck.py checking the correctness of the sequence of candles for the occasion.
the
data Analysis
Make a simple class that will contain methods to search for patterns and convert them into vectors for machine learning algorithms:
the
import psycopg2
from Conf import DbConfig, Config
from Desc.Candle import Candle
from Desc.Pattern import Pattern
import numpy
def get_patterns_for_window_and_num(window, length, limit=None):
conf = Config.Config()
dbConf = DbConfig.DbConfig()
connect = psycopg2.connect(database=dbConf.dbname, user=dbConf.user, host=dbConf.address, password=dbConf.password)
cursor = connect.cursor()
print 'Successfully connected'
tName = conf.insName.lower()
cmd = 'SELECT COUNT(*) FROM {0};'.format(tName)
cursor.execute(cmd)
totalCount = cursor.fetchone()[0]
print 'Total items count {0}'.format(totalCount)
cmd = 'SELECT * FROM {0} ORDER BY datetimestamp'.format(tName)
if limit is None:
cmd = '{0};'.format(cmd)
else:
cmd = '{0} LIMIT {1};'.format(cmd, limit)
wl = list()
patterns = list()
profits = list()
indicies = list()
i = 1
for row in cursor:
nextCandle = Candle(row[0], row[1], row[2], row[3])
wl.append(nextCandle)
print 'Row {0} of {1}, {2:.3f}% total'.format(i, totalCount, 100*(float(i)/float(totalCount)))
if len(wl) == window+length:
# find pattern of length 0..elements
# that indicates price falls / grows
# in the next window elements to get profit
candle = wl[length-1]
ind = length + 1
# take real data only
if candle.volume != 0:
while ind < = window + length:
iCandle = wl[ind-1]
# define patterns for analyzing iCandle
if iCandle.volume != 0:
if iCandle.bid > candle.ask:
# buy pattern
p = Pattern(wl[:length],'buy')
patterns.append(p)
indicies.append(ind - length)
profits.append(iCandle.bid - cap.ask)
break
if iCandle.ask < cap.bid:
# sell pattern
p = Pattern(wl[:length],'sell')
patterns.append(p)
indicies.append(ind - length)
profits.append(cap.bid - iCandle.ask)
break
ind = ind + 1
wl.pop(0)
i = i + 1
print 'Total patterns: {0}'.format(len(patterns))
print 'Mean index[after]: {0}'.format(numpy.mean(indicies))
print 'Mean profit: {0}'.format(numpy.mean(profits))
connect.close()
return patterns
def pattern_serie_to_vector(pattern):
sum = 0
for candle in the pattern.serie:
sum = sum + float(cap.ask + candle.bid) / 2;
mean = sum / len(pattern.serie)
vec = []
for candle in the pattern.serie:
vec = numpy.hstack((vec [ (cap.ask+candle.bid) / (2 * mean) ]))
return vec
def get_x_y_for_patterns(patterns, expected_result):
X = []
y = []
for p in patterns:
X. append(pattern_serie_to_vector(p))
if (p.result == expected_result):
y.append(1)
else:
y.append(0)
return X, y
In the first method, as the times describes the conditions for selecting patterns, and the latter returns the vectors for the algorithms. Pay attention to the method pattern_serie_to_vector, which normalizes the data. As mentioned above, prices may be different, and same (similar to the analysis of the pattern of the triangle, no matter what the price, it is important to the mutual arrangement of successive candles).
And now the most interesting, will check the results of two classifiers is gradient boosting and linear regression. We estimate the area under the ROC curve (AUC_ROC) for crossvalidation for 5 blocks, depending on the settings of the algorithm.
Recall that the area under the ROC curve changes its value from 0.5 (the worst classification) to 1 (the best classification). Our goal is to get at least 0.8.
Check some of the classifiers and choose the best, as well as the length of the series of the pattern and the window.
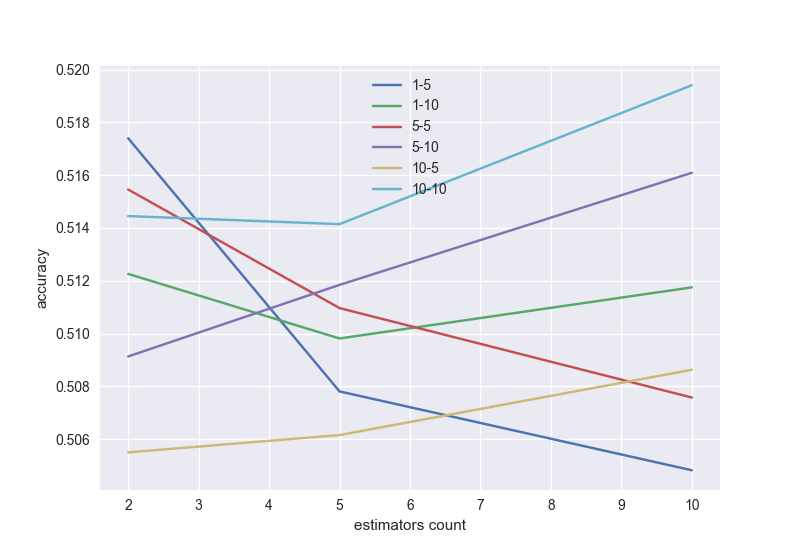
Gradient boosting, with a possible bust by the length of the series and the window (in a good model with increasing number of trees, the accuracy needs to grow, so you need to choose the suitable length of the series and window):
the
# gradient boosting
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import KFold, cross_val_score
from sklearn.ensemble import GradientBoostingClassifier
from PatternsCollector import get_patterns_for_window_and_num, get_x_y_for_patterns
import seaborn
nums = [2,5,10]
i = 0
wrange = [1,5,10]
lrange = [5,10]
values = list()
legends = list()
for wnd in wrange:
for l in lrange:
scores = []
patterns = get_patterns_for_window_and_num(wnd, l)
X, y = get_x_y_for_patterns(patterns, 'buy')
for n in nums:
i = i+1
kf = KFold(n_splits=5, shuffle=True, random_state=100)
model = GradientBoostingClassifier(n_estimators=n, random_state=100)
ms = cross_val_score(model, X, y, cv=kf, scoring='roc_auc')
scores.append(np.mean(ms))
print 'Calculated {0}-{1}, num={2}, {3:.3f}%'.format(wnd, l, n, 100 * i/float((len(nums)*len(wrange)*len(lrange))))
values.append(scores)
legends.append('{0}-{1}'.format(wnd, l))
plt.xlabel('estimators count')
plt.ylabel('accuracy')
for v in values:
plt.plot(nums, v)
plt.legend(legends)
plt.show()
Similarly, linear regression with tuning parameters:
the
# logistic regression
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from PatternsCollector import get_patterns_for_window_and_num, get_x_y_for_patterns
from sklearn.model_selection import KFold, cross_val_score
import numpy as np
import matplotlib.pyplot as plt
import seaborn
cr = [10.0 ** i for i in range(-3, 1)]
i = 0
wrange = [1,5,10]
lrange = [5, 10]
values = list()
legends = list()
for wnd in wrange:
for l in lrange:
scores = []
patterns = get_patterns_for_window_and_num(wnd, l)
X, y = get_x_y_for_patterns(patterns, 'buy')
sc = StandardScaler()
X_sc = sc.fit_transform(X)
for c in cr:
i = i+1
kf = KFold(n_splits=5, shuffle=True, random_state=100)
model = LogisticRegression(C=c, random_state=100)
ms = cross_val_score(model, X_sc, y, cv=kf, scoring='roc_auc')
scores.append(np.mean(ms))
print 'Calculated {0}-{1}, C={2}, {3:.3f}%'.format(wnd, l, c, 100 * i/float((len(cr)*len(wrange)*len(lrange))))
values.append(scores)
plt.xlabel('C value')
plt.ylabel('accuracy')
for v in values:
plt.plot(cr, v)
plt.legend(legends)
plt.show()
As I said, the conditions are incomplete. Therefore, the resulting accuracy is only 0.52. But if you complete, then the accuracy will be better. Can try other algorithms, neural networks, random forest and many others. We must not forget about the problem of retraining — for example, when a large number of trees in gradient boosting.
Check for errors in the code: if instead of real data in the database to take from them, sin(), for both classifiers AUC_ROC on crossvalidation is 0.96.
the
Trading robot
In conclusion, I suggest you code a trading robot that can put the application on a demo account and for real. Most importantly — closing deals it builds a histogram of profits in the transaction, based on information received from the broker. That is, you actually will be able to verify your trading strategy.
the
import datetime
from datetime import datetime
from os import path
import matplotlib.pyplot as plt
import oandapyV20
import oandapyV20.endpoints.orders as orders
import oandapyV20.endpoints.positions as positions
from oandapyV20.contrib.import requests MarketOrderRequest
from oandapyV20.contrib.import requests TakeProfitDetails, StopLossDetails
from oandapyV20.endpoints.import accounts AccountDetails
from oandapyV20.endpoints.pricing import PricingInfo
from Conf.Config import Config
import seaborn
config = Config()
oanda = oandapyV20.API(environment=config.env, access_token = config.token)
pReq = PricingInfo(config.account_id, 'instruments='+config.insName)
asks = list()
bids = list()
long_time = datetime.now()
short_time = datetime.now()
if config.write_back_log:
f_back_log = open(path.relpath(config.back_log_path + '/' + config.insName + '_' + datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))+'.log', 'a');
time = 0
times = list()
last_ask = 0
last_bid = 0
if config.write_back_log:
print 'Backlog file name:', f_back_log.name
f_back_log.write('DateTime,Instrument,ASK,BID,Price change,Status, Spread, Result \n')
def process_data(ask, bid, status):
global last_result
global last_ask
global last_bid
global long_time
global short_time
if status != 'tradeable':
print config.insName, 'is halted.'
return
asks.append(ask)
bids.append(bid)
times.append(time)
# --- begin strategy here ---
# --- end strategy here ---
if len(asks) > config.maxLength:
asks.pop(0)
if len(bids) > config.maxLength:
bids.pop(0)
if len(times) > config.maxLength:
times.pop(0)
if config.write_back_log:
f_back_log.write('%s,%s,%s,%s,%s,%s,%s \n' % (datetime.datetime.now(), config.insName, pReq.response.get('prices')[0].get('asks')[1].get('price'), pReq.response.get('prices')[0].get('bids')[1].get('price'), pChange, the ask-bid result))
def do_long(ask):
if config.take_profit_value!=0 or config.stop_loss_value!=0:
order = MarketOrderRequest(instrument=config.insName,
units=config.lot_size,
takeProfitOnFill=TakeProfitDetails(price=ask+config.take_profit_value).data
stopLossOnFill=StopLossDetails(price=ask-config.stop_loss_value).data)
else:
order = MarketOrderRequest(instrument=config.insName,
units=config.lot_size)
r = orders.OrderCreate(config.account_id, data=order.data)
resp = oanda.request(r)
print resp
price = resp.get('orderFillTransaction').get('price')
print time, 's: BUY price =', price
return float(price)
def do_short(bid):
if config.take_profit_value!=0 or config.stop_loss_value!=0:
order = MarketOrderRequest(instrument=config.insName,
units=config.lot_size,
takeProfitOnFill=TakeProfitDetails(price=bid+config.take_profit_value).data
stopLossOnFill=StopLossDetails(price=bid-config.stop_loss_value).data)
else:
order = MarketOrderRequest(instrument=config.insName,
units=config.lot_size)
r = orders.OrderCreate(config.account_id, data=order.data)
resp = oanda.request(r)
print resp
price = resp.get('orderFillTransaction').get('price')
print time, 's: SELL price =', price
return float(price)
def do_close_long():
try:
r = positions.PositionClose(config.account_id, 'EUR_USD', {"longUnits": "ALL"})
resp = oanda.request(r)
print resp
pl = resp.get('longOrderFillTransaction').get('pl')
real_profits.append(float(pl))
print time, 's: Closed. Profit = ', pl, ' price = ', resp.get('longOrderFillTransaction').get('price')
except:
print 'No long units to close'
def do_close_short():
try:
r = positions.PositionClose(config.account_id, 'EUR_USD', {"shortUnits": "ALL"})
resp = oanda.request(r)
print resp
pl = resp.get('shortOrderFillTransaction').get('tradesClosed')[0].get('realizedPL')
real_profits.append(float(pl))
print time, 's: Closed. Profit = ', pl, ' price = ', resp.get('shortOrderFillTransaction').get('price')
except:
print 'No short units to close'
def get_bal():
r = AccountDetails(config.account_id)
return oanda.request(r).get('account').get('balance')
plt.ion()
plt.grid(True)
do_close_long()
do_close_short()
real_profits = list()
while True:
try:
oanda.request(pReq)
ask = float(pReq.response.get('prices')[0].get('asks')[0].get('price'))
bid = float(pReq.response.get('prices')[0].get('bids')[0].get('price'))
status = pReq.response.get('prices')[0].get('status')
process_data(ask, bid, status)
plt.clf()
plt.subplot(1,2,1)
plt.plot(times, asks, color='red', label='ASK')
plt.plot(times, bids, color='blue', label='BID')
if last_ask!=0:
plt.axhline(last_ask, linestyle=':', color='red', label='curr ASK')
if last_bid!=0:
plt.axhline(last_bid, linestyle=':', color='blue', label='curr BID')
plt.ylabel('Price change')
plt.legend(loc='upper left')
plt.subplot(1, 2, 2)
plt.hist(real_profits, label='Profits')
plt.legend(loc='upper left')
plt.xlabel('Profits')
plt.ylabel('Counts')
plt.tight_layout()
except Exception as e:
print e
plt.pause(config.period)
time = time + config.period
The complete source code for here.
I hope I saved time for those who are interested in algorithmic trading. After all, now to test Your ideas you just need to change the code to run the robot and get statistics on Your deals from the broker. And you can perform almost any stock data.
Special thanks want to say to the authors of the course from the Yandex machine learning on Coursera. And Andrew Ng for a wonderful lecture on the same resource.
UPDATE:
But what happens on gradient boosting for futures bonded to SI with Finam over the last year (if under the selection criteria of the pattern to understand the jump in prices of 1% in the right direction):
This is already a good result. The expectation of a plus.
And then just alpha Direct has released a new server-side API :)

